Codice criptato: Trasmissione efaptica
Codice criptato: Trasmissione efaptica
Riassunto

Il termine di 'Rete Neurale Cognitiva' abbreviata in 'RNC' è un processo intellettuale cognitivo dinamico del clinico che interroga la rete per auto-addestrarsi. La 'RNC' non è una 'Machine Learning' perchè mentre quest'ultima deve essere addestrata dal clinico, con aggiustamenti statistici e di predizione, la 'RNC' addestra il clinico o meglio indirizza il clinico alla diagnosi pur essendo sempre interrogata seguendo una logica umana, da qui il termine 'cognitiva'. Come dimostrato la definizione di 'Spasmo Emimasticatorio' nella nostra paziente Mary Poppins non è stato un percorso clinicamente semplice, tuttavia, considerando i temi presentati nei capitoli precedente di Masticationpedia abbiamo a disposizione almeno tre elementi di supporto: una visione di 'Probabilità quantistica' dei fenomeni fisico chimici nei sistemi complessi biologici di cui si parlerà diffusamente nei capitoli specifici; un linguaggio più formale e meno vago rispetto al linguaggio naturale che indirizza l'analisi diagnostica al primo nodo di input della 'RNC' attraverso lo 'Demarcatore di Coerenza ' descritto nel capitolo '1° Clinical case: Hemimasticatory spasm; il processo della 'RNC' che essendo gestito e guidato esclusivamente dal clinico diviene un mezzo imprenscindibile per la diagnosi definitiva. La 'RNC', infatti, è il risultato di un profondo processo cognitivo che si esegue su ogni passaggio dell'analisi in cui il clinico pesa le proprie intuizioni, chiarisce i propri dubbi, valuta i referti, considera i contesti ed avanza step by step confrontandosi con il risultato della risposta proveniente dal database che nel nostro caso è Pubmed e che sostanzialmente rappresenta l'attuale livello di conoscenza di base al tempo dell'interrogazione ed il nei più ampi contesti specialistici.



Introduzione
Nel capitolo '1° Clinical case: Hemimasticatory spasm' siamo giunti subito a conclusione bypassando tutto il processo cognitivo, clinico e scientifico che è alla base della definizione diagnostica ma non è così semplice altrimenti la nostra povera paziente Mary Poppins non avrebbe dovuto aspettare 10 anni per la diagnosi corretta.
Va rimarcato che non si tratta di negligenza da parte dei clinici piuttosto di complessità dei 'Sistemi Complessi biologici' e soprattutto da una forma mentis ancorata, ancora, ad una 'Probabilità classiche' che categorizza i fenotipi sani e malati in funzione dei sintomi e segni clinici campionati invece di sondare lo 'Stato' di sistema nell'evoluzione temporale. Questo concetto, anticipato nel capitolo 'Logic of medical language: Introduction to quantum-like probability in the masticatory system' ed in 'Conclusions on the status quo in the logic of medical language regarding the masticatory system' ha gettato le basi per un linguaggio medico più articolato e meno deterministico, focalizzato principalmente sullo 'Stato' di 'Sistema mesoscopico' il cui scopo è, essenzialmente, quello di decriptare il messaggio in linguaggio macchina generato dal Sistema Nervoso Centrale come assisteremo nella descrizione di altri casi clinici che verranno riportati nei prossimi capitoli di Masticationpedia.
Questo modello, che proponiamo con il termine di 'Rete Neurale Cognitiva' abbreviata in 'RNC' è un processo intellettuale cognitivo dinamico del clinico che interroga la rete per auto-addestrarsi. La 'RNC' non è una 'Machine Learning' perchè mentre quest'ultima deve essere addestrata dal clinico, con aggiustamenti statistici e di predizione, la 'RNC' addestra il clinico o meglio indirizza il clinico alla diagnosi pur essendo sempre interrogata seguendo una logica umana, da qui il termine 'cognitiva'.
Alcuni modelli di machine learning classici, infatti, il cui addestramento in laboratorio dà risultati positivi, falliscono applicati al contesto reale. Questo, in genere, è attribuito a una mancata corrispondenza tra i set di dati con i quali la macchina è stata addestrata e i dati che, invece, incontra nel mondo reale. Un esempio pratico di ciò può essere rappresentato dal conflitto di asserzioni incontrato nel processo diagnostico della nostra paziente Mary Poppins tra il contesto odontoiatrico e neurologico che solo il supporto del demarcatore di coerenza (processo cognitivo) è riuscito a risolvere.
Uno dei limiti del machine learning, dunque, è noto come “data shift”,[1] ovvero “spostamento dei dati” ed un’altra causa alla base del fallimento di alcuni modelli fuori dal laboratorio, è la “sottospecificazione“[2][3] tanto è vero che il tentativo di costruire un sistema EMR ( cartella clinica elettronica) potenziato con algoritmo progettato specificamente per l'uso in un centro oncologico, fu un fallimento notevole con un costo stimato di $ 39.000.000 USD. Questo sforzo è stato una partnership del 2012 tra M.D. Anderson Partners e IBM Watson a Houston, in Texas.[4] Le prime notizie promozionali che descrivevano il progetto affermavano che il piano era quello di combinare dati genetici, rapporti patologici con note dei medici e articoli di riviste pertinenti per aiutare i medici a elaborare diagnosi e trattamenti. Tuttavia, cinque anni dopo, nel febbraio 2017, M.D. Anderson ha annunciato di aver chiuso il progetto poiché, dopo diversi anni di tentativi, non aveva prodotto uno strumento da utilizzare con i pazienti che fosse pronto per andare oltre i test pilota.
(... il modello è essenzialmente semplice nella sua complessità cognitiva)
In sostanza il messaggio criptato in linguaggio macchina inviato all'esterno dal Sistema Nervoso Centrale nei 10 anni di malattia della nostra paziente Mary Poppins veniva interpretato attraverso un linguaggio verbale come Dolore Orofacciale da Disordini Tempormandibolari'. Abbiamo rimarcato più volte, però, che il linguaggio verbale umano è distorto dalla vaghezza e dalla ambiguità perciò non essendo un linguaggio formale, come quello matematico, può generare errori diagnostici. Il messaggio in linguaggio macchina inviato all'esterno dal Sistema Nervoso Centrale da ricercare non è il dolore ( il dolore è un linguaggio verbale) ma l'anomalia di 'Stato di Sistema' in cui l'organismo si trovava in quel periodo temporale. Da qui lo shiftamento dalla semeiotica del sintomo e del segno clinico alla 'Logica di Sistema' che attraverso modelli di 'Teoria dei sistemi' quantificano le risposte del sistema da stimoli in entrata, anche nei soggetti sani.
Tutto ciò viene replicato nel modello proposto di 'RNC' andando a suddividere il processo in trigger in entrata (Input) e dati in uscita (Output) per poi essere reiterati in un loop gestito cognitivamente dal clinico fino alla generazione di un singolo nodo utile per la diagnosi definitiva. Il modello, sostanzialmente, si articola nel seguente modo:
- Input: Per trigger in entrata si intende il processo cognitivo che il clinico attua in funzione delle considerazioni pervenute da precedenti asserzioni, come è stato puntualizzato nei capitoli riguardanti la 'Logica di linguaggio medico'. Nel nostro caso, attraverso il 'Demarcatore di coerenza è stato definito idoneo il contesto neurologico invece dell'odontoiatrico che perseguiva una spiegazione clinico diagnostica di TMDs. Questo trigger è di essenziale importanza perchè permette al clinico di centrare il comando di iniziazione di analisi delle rete che connetterà un ampio campione di dati corrispondenti al trigger impostato. A questo essenziale comando iniziale, come chiave algoritmica di decriptazione, si aggiunge l'ultimo comando di chiusura che è altrettanto importante in quanto dipende dall'intuizione del clinico il quale reputerà finito il processo di decriptazione. In Figura 1, viene rappresentata la struttura della 'RNC' in cui si può notare la differenza tra le più comuni strutture di rete neurali in cui il primo stadio è strutturato con un elevato numero di variabili in entrata. Nella nostra 'RNC' il primo stadio corrisponde solo ad un nodo e precisamente al comando di inizializzazione di analisi della rete denominato 'Demarcatore di Coerenza ', i successivi loop della rete, che permettono al clinico di terminare oppure il reiterare della rete, ( 1st loop open, 2st loop open,...... nst loop open) sono determinanti per concludere il processo di decriptazione ( Decrypted Code). Questo passaggio verrà spiegato più dettagliatamente a seguire nel capitolo.

- Output: I dati in uscita dalla rete, che sostanzialmente corrispondono ad un precisa richiesta trigger cognitiva, restituisce un numero ampio di dati classificati e correlati alla keyword richiesta. Il clinico dovrà dedicare tempo e concentrazione per proseguire nella decriptazione del codice macchina. Abbiamo assistito, infatti, come seguendo le indicazioni dettate da criteri di ricerca come lo 'Research Diagnostic Criteria' (RDC) la nostra paziente Mary Poppins sia stata immediatamente categorizzata come 'TMDs' ed abbiamo anche suggerito il modo per ampliare le capacità diagnostiche in odontoiatria attraverso un modello 'fuzzy' che permetterebbe di spaziare in contesti diversi da quello proprio. Ciò mostra la complessità nel fare diagnosi differenziale e le difficoltà nel seguire un roadmap semeiotica classica perchè si è ancorati troppo al linguaggio verbale e poco ad una cultura quantistica dei sistemi biologici. Ciò sconfina nel concetto di linguaggio macchina e comando iniziale di decriptazione che andremo a spiegare brevemente nel prossimo paragrafo.
Comando di iniziazione
Per un momento immaginiamo che il cervello parli la lingua di un computer e non viceversa come avviene in ingegneria, per distinguere la già citata differenza tra linguaggio macchina e linguaggio verbale umano. Per scrivere una frase, una parola oppure una formula il computer non usa la modalità classica verbale (alfabeto) oppure la modalità decimale (numeri) con cui noi scriviamo formule matematiche ma un suo codice di linguaggio di 'scrittura' chiamato per il web codice html. Prendiamo come esempio la scrittura di una formula abbastanza complessa, essa si presenta al nostro cervello nel linguaggio verbale con cui noi abbiamo imparato a leggere una equazione matematica, nella seguente forma:
ed immaginiamo, lasciando spaziare la mente, che questa formula corrisponda al messaggio del Sistema Nervoso Centrale, come abbiamo anticipato, ed in particolare nella 'Trasmissione Efaptica' ancora da decriptare

Il computer e dunque il cervello, per il nostro esempio metaforico, non conosce il linguaggio verbale o meglio è solo una convenzione generata per semplificare la comunicazione naturale, piuttosto ne ha uno suo proprio con cui scrivere la formula citata e nel linguaggio wiki testo ( con estensione .php) si presenta nel seguente modo rappresentato in figura 2:
 Figura 2: Wiki testo di una formula matematica. Notare il comando <math> di inizializzazione ed il comando </math> di chiusura dello script
Figura 2: Wiki testo di una formula matematica. Notare il comando <math> di inizializzazione ed il comando </math> di chiusura dello scriptcome si può notare non c'entra nulla con il linguaggio verbale ed infatti, il cervello ha un suo proprio linguaggio macchina costituito non da vocali, consonanti e numeri bensì da potenziali d'azione, pacchetti d'onda, frequenze ed ampiezze, popoli elettrici, ecc. ciò che semplicemente osserviamo in un tracciato elettroencefalografico (EEG) e che rappresenta, appunto, i campi elettromagnetici sullo scalpo dell’attività dei dipoli e delle correnti ioniche cerebrali che si propagano nel volume encefalico.

La favola, però, non finisce qui perchè questo è un linguaggio di scrittura che nulla ha a che vedere con l'interprete del hardware del computer e dunque della struttura organica del cervello fatta di Centri con funzioni specializzate, circuiterie sinaptiche, polisinaptiche e quant'altro. Questo linguaggio di scrittura, dunque, deriva da un linguaggio macchina che non si modella nel comando '<math>' piuttosto che '+2\sum_{\alpha_1'} ma deriva da un linguaggio binario successivamente convertito in codice di scrittura html. Questo è definito come 'Linguaggio macchina' sia per il computer che per il cervello e si può simulare nel seguente modo
00101011 00110010 01011100 01110011 01110101 01101101 01011111 01111011 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110001 00111100 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110010 01111101 01011100 01100011 01101111 01110011 01011100 01110100 01101000 01100101 01110100 01100001 01011111 01111011 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110001 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110010 01111101 01011100 01110011 01110001 01110010 01110100 01111011 01010000 00101000 01000001 00111101 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110001 00101001 01010000 00101000 01000010 00111101 01011100 01100010 01100101 01110100 01100001 01111100 01000001 00111101 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110001 00101001 01111101 00100000 01010000 00101000 01000001 00111101 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110010 00101001 00001010 01010000 00101000 01000010 00111101 01011100 01100010 01100101 01110100 01100001 01111100 01100001 00111101 01011100 01100001 01101100 01110000 01101000 01100001 01011111 00110010 00101001
Ma cosa succede se in questo codice non fosse presente la seguente stringa 00101011 00110010 01011100 01110011 01110101 01101101 che corrisponde al comando <math> ?
Il messaggio sarebbe corrotto e la formula non si genererebbe per mancanza del più importante step quello di 'Inizializzazione del codice di comando', così pure se eliminassimo l'ultimo parte di codice 01101100 01110000 01101000 01100001 01011111 00110010 00101001, corrispondente alla chiusura dello script </math> la formula rimarrebbe corrotta ed indeterminata.
In pratica senza il comando iniziale e finale la formula ben descritta nel seguente forma a noi comprensibile:
si presenterebbe in un modo incomprensibile alla maggioranza delle persone.
+2\sum_{\alpha_1<\alpha_2}\cos\theta_{\alpha_1\alpha_2}\sqrt{P(A=\alpha_1)P(B=\beta|A=\alpha_1)} P(A=\alpha_2) P(B=\beta|a=\alpha_2)
Cosí come la mancanza di parte del codice binario corrompe la rappresentazione della formula similmente la decriptazione del linguaggio macchina del SNC é fonte di vaghezza ed ambiguità del linguaggio verbale e contestualmente di errore diagnostico.
Processo cognitivo
Il cuore del modello 'RNC' sta nel processo cognitivo riferito esclusivamente al clinico che ha in mano il timone mentre la rete rimane sostanzialmente la bussola che avverte del fuori rotta e/o suggerire altre rotte alternative ma la responsabilità decisionale è sempre riferita al clinico ( mente umana). In questo semplice definizione, lo percepiremo meglio a fine del capitolo, il sinergismo 'Rete neurale' e 'Processo cognitivo umano' del clinico sarà auto-implementante perchè da un lato il clinico viene addestrato o meglio guidato dalla rete neurale ( database) e quest'ultima verrà addestrata all'ultimo evento scientifico-clinico aggiornato. In sostanza la diagnosi definitiva aggiungerà un dato informativo in più alla conoscenza di base temporale . Questo modello differisce sostanzialmente dal 'machine Learning' già solo osservando i due modelli nella loro configurazione strutturale ( Figura 1 e 3).


Nella figura 3 viene rappresentato una tipica rete neurale, note anche come NN artificiali. Queste NN artificiali tentano di utilizzare più livelli di calcoli per imitare il concetto di come il cervello umano interpreta e trae conclusioni dalle informazioni.[5] NN sono essenzialmente modelli matematici progettati per gestire informazioni complesse e disparate e la nomenclatura di questo algoritmo deriva dal suo uso di "nodi" simili alle sinapsi nel cervello.[6] Il processo di apprendimento di un NN può essere supervisionato o non supervisionato. Si dice che una rete neurale apprenda in modo supervisionato se l'output desiderato è già mirato e introdotto nella rete mediante l'addestramento dei dati mentre NN non supervisionato non ha tali output target preidentificati e l'obiettivo è raggruppare unità simili vicine in determinate aree del intervallo di valori. Il modulo supervisionato prende i dati (ad es. sintomi, fattori di rischio, risultati di laboratorio e di imaging) per l'addestramento su esiti noti e cerca diverse combinazioni per trovare la combinazione più predittiva di variabili. NN assegna più o meno peso a determinate combinazioni di nodi per ottimizzare le prestazioni predittive del modello addestrato.[7]
La figura 1, invece, corrisponde al modello 'RNC' proposto e si può notare come il primo stadio di acquisizione è composto da un solo nodo mentre le 'Machine learning' al primo nodo più variabili in entrata hanno maggiore è la 'Predizione' in uscita. Si tenga conto, come detto, che il primo nodo ha un importanza fondamentale perchè deriva già da un processo cognitivo clinico che ha condotto il 'Demarcatore di Coerenza ' a determinare una prima assoluta scelta di campo. Dal comando di inizializzazione, dunque, la rete neurale si evolve in una serie di stati composti da un numero elevato di nodi per poi terminare ad un primo step di uno o due nodi per poi reiterare in un successivo loop di più nodi fino a terminarsi nell'ultimo nodo conclusivo ( decriptazione del codice). Il processo di inizializzazione del primo nodo, l'ultimo ed il rieiterare del loop è esclusiva del processo cognitivo umano del clinico e non di un automatismo statistico della machine learning tanto meno di stadi 'Hidden'. Tutti i loop aperti e chiusi devo essere conosciuti dal clinico.
Per un approfondimento sull'argomento è disponibile su Masticationpedia al capitolo 'An artificially intelligent (or algorithm-enhanced) electronic medical record in orofacial pain'
Ma vediamo nel dettaglio come si edifica una 'RNC'
Rete Neurale Cognitiva
In questo paragrafo ci sembra doveroso spiegare il processo clinico seguito con il supporto della 'RNC' seguendo step by step le interrogazioni cognitive alla rete e l'analisi cognitiva eseguita sui dati in risposta dalla rete. La mappa è stata anche riportata in figura 4 con i links alle risposte della rete che posso essere visualizzate per una più consistente documentazione:
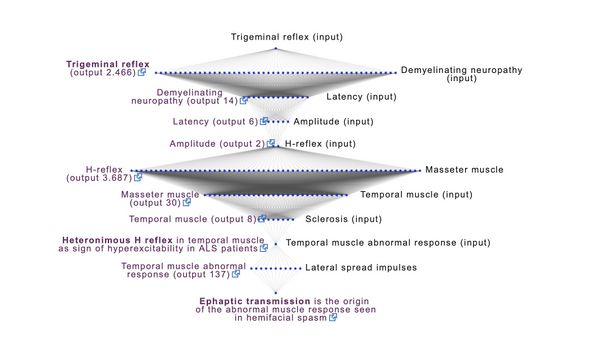
- Demarcatore di Coerenza : Come abbiamo precedente descritto il primo stap è un comando di inizializzazione di analisi della rete che deriva, appunto, da una precedente elaborazione cognitiva delle asserzioni nel contesto odontoiatrico e quello neurologico a cui lo 'Demarcatore di Coerenza ' ha dato un peso assoluto eliminando, di fatto, dal processo il contesto odontoiatrico . Da quanto emerge dalle asserzioni neurologiche lo 'Stato' del Sistema Nervoso Trigeminale appare destrutturato evidenziando anomalie dei riflessi trigeminali per cui il comando di 'Inzializzazione' è lo 'Trigeminal Reflex' per andare a testare il database ( Pubmed).
- 1st loop open: Questo comando di 'Inizializzazione', perciò, viene considerato come input iniziale per il database Pubmed che risponde con 2.466 dati clinici e sperimentali a disposizione del clinico. L'apertura della prima vera analisi cognitiva viene elaborata proprio sull'analisi del primo risultato della 'RNC' corrispondente a 'Trigeminale Reflex'. In questa fase ci si rende conto che una discreta percentuale di dati rilevano una corrispondenza tra anormalità dei riflessi trigeminali e problematiche di demielinizzazione per cui il 1st loop open corrisponderà a: ' Demyelinating neuropathy' che restituirà 14 dati sensibili. Dietro la scelta di questa key c'è un prpcesso cognitivo attivo e dinamico del clinico. Dalle asserzioni nel contesto neurologico è stata ipotizzato una patologia neuropatica in cui considerare anche l'aspetto demielinizzante.
- 2st loop open: Il processo continua focalizzando sempre più dettagliatamente le keywords che corrispondo al nostro dato elettrofisiologico risultato anomalo e cioè la latenza del jaw jerk. Questo input corrispondente a 'Latency' e restituisce 6 dati sensibili su cui elaborare un ulteriore reiterare del loop.
- 3st loop open: Nelle asserzioni del contesto neurologico si osserva una anomalia anche di ampiezza del jaw jerk oltre che di latenza. Questo 3st loop open corrisponde a ' Amplitude' e restituisce solo 2 dati su cui soffermarci per decidere la keyword per reiterare il loop oppure chiudere definitivamente il processo. Dal risultato si evince un articolo che descrive la valutazione elettrofisiologica delle neuropatie craniche che è stato considerato di basso peso specifico per i nostri scopi mentre l'altro articolo mette in evidenza alcune metodologie trigeminali per testare latenza, ampiezza dei muscoli masticatori tra cui H-reflex.
- 4st loop closed: Il processo, perciò, continua inserendo la keywords algoritmica ' H-reflex ' che restituisce 3.701 dati scientifico clinici.
- 5st loop open: Le anomalie evidenziate sono state principalmente verificate sui masseteri per cui si deduce che nel campione interrogato del 4st loop closed possano essere intercettati keywords riguardanti il muscolo 'Masseter muscle', da qui il 5st loop open che restituisce 30 dati disponibili per la 'RNC'
- 6st loop open: Noi, però, non sappiamo se il danno neuropatico sia localizzato esclusivamente sul muscolo massetere oppure coinvolga anche il muscolo temporale per cui una ulteriore keywords algoritmica sarebbe la ' Temporal muscle' che restituisce 8 dati sensibili.
- 7st loop open: Da una analisi acurata di questo 7st loop open ci si domanda se queste anomalie elettrofisiologiche possano essere evidenziate nei pazienti con sclerosis ed essendo presente nella storia clinica della paziente, una precedente diagnosi di 'Morfea' si è optato per interrogare la 'Rete' di un ulteriore keyword e focalizzata in 'Sclerosi' che ha dato un solo dato sensibile 'H-refex eteronima sul muscolo temporale nei pazienti con Sclerosi Laterale Amiotrofica.
- 8st loop closed: In questo singolo nodo il clinico potrebbe terminare il loop ma non avrebbe risolto nulla perchè non si è giunti ancora alla decodifica del messaggio criptato. Da notare che la metodica elettrofisiologica denominata 'H-reflex eteronoma' è in grado di evidenziare anomalie di risposta dal muscolo temporale per cui si è continuato il loop inserendo la seguente keyword specifica, ' Temporal muscle abnormal response' che restituisce 137 dati.
- 9st loop open: Studiando i 137 articoli apparsi in Pubmed il clinico intuisce che le anormalità di risposta nel muscolo temporale attraverso il test della H-reflex dipendono da uno spread della corrente da stimolo nell'arsone destrutturato e quindi approfondisce ulteriormente il loop interrogando la rete di un ulteriore keyword la ' Lateral spera impulses' che chiude definitivamente il processo cognitivo della 'Rete Neurale' con un ravvicinato articolo alle nostre ipotesi cliniche che riguardano la paziente Mary Poppins e cioè 'Ephaptic transmission is the origin of the abnormal muscle response seen in hemifacial spasm'



Conclusione
Come dimostrato la definizione di 'Spasmo Emimasticatorio' nella nostra paziente Mary Poppins non è stato un percorso clinicamente semplice, tuttavia, considerando i temi presentati nei capitoli precedente di Masticationpedia abbiamo a disposizione almeno tre elementi di supporto:
- Una visione di 'Probabilità quantistica' dei fenomeni fisico chimici nei sistemi complessi biologici di cui si parlerà diffusamente nei capitoli specifici.
- Un linguaggio più formale e meno vago rispetto al linguaggio naturale che indirizza l'analisi diagnostica al primo nodo di input della 'RNC' attraverso lo 'Demarcatore di Coerenza ' descritto nel capitolo '1° Clinical case: Hemimasticatory spasm'
- Il processo della 'RNC' che essendo gestito e guidato esclusivamente dal clinico diviene un mezzo imprenscindibile per la diagnosi definitiva.
La 'RNC', infatti, è il risultato di un profondo processo cognitivo che si esegue su ogni passaggio dell'analisi in cui il clinico pesa le proprie intuizioni, chiarisce i propri dubbi, valuta i referti, considera i contesti ed avanza step by step confrontandosi con il risultato della risposta proveniente dal database che nel nostro caso è Pubmed che sostanzialmente rappresenta l'attuale livello di conoscenza di base al tempo dell'interrogazione ed il nei più ampi contesti specialistici.
Una rappresentare lineare di questo processo cognitivo etichettata come con le dovute annotazioni potrebbe essere il seguente:

Trigeminal Reflex,Demyelinating neuropathy, Latency,Amplitude,H-reflex, Masseter muscle, Temporal muscle, H-refex eteronima sul muscolo temporale nei pazienti con Sclerosi Laterale Amiotrofica,Temporal muscle abnormal responseEphaptic transmission is the origin of the abnormal muscle response seen in hemifacial spasm



Le annotazioni da rimarcare sono sostanzialmente due: la prima è l'inderogabile individuazione dell'input di inizializzazione che deriva dal contesto scelto attraverso il 'Demarcatore di Coerenza e la seconda l'ordine delle keywords cognitivamente selezionate.
Contrassegnando la rete come con un input di inizializzazione odontoiatrico ( Temporomandibular disorders) nel modo seguente:

Temporomandibular Disorders,Trigeminal reflex, Demyelinaying neuropathy, LatencySide asymmetry of the jaw jerk in human craniomandibular dysfunction

Il messaggio risulta corrotto, come precedente esposto riguardo la formula matematica, in quanto l'input di comando di inizializzazione ( Tempormandibular disorders) indirizza la rete per un insieme di dati, ben 20.514, che perdono le connessioni con una parte di sottoinsiemi. Pur mantenendo il resto della RNC simile alla precedente ( contesto neurologico) la rete si ferma alla keyword 'latency' mostrando un solo articolo scientifico che riguarda, ovviamente, la latenza del jaw jerk ma non correlata a disturbi neuropatici.( figura 5) L'errore nella scelta dell'input di comando di inizializzazione del processo RNC non solo corrompe il messaggio da decriptare ma rende vano tutto il lavoro a monte di analisi delle asserzioni cliniche discusso nei capitoli di logica di linguaggio.

Cambiando l'ordine, invece, delle keywords in un esatto percorso cognitivo come quello neurologico sostanzialmente restituisce gli stessi risultati del precedente purché l'input di comando di inizializzazione sia perfettamente centrato, come si può notare nel seguente simulazione etichettata con :

Trigeminal reflex, amplitude latency demyelinating neuropathy H-reflex................

e si riconnette al precedente fino a chiudersi nello output 'Ephaptic transmission is the origin of the abnormal muscle response seen in hemifacial spasm' ( Figura 6)

Da notare che se questo capitolo fosse stato pubblicato su una rivista Scientifica Internazionale impattata ( Inpact Factor) lo e contestualmente una ipotetica 'machine learning' si sarebbero arricchiti di un nuovo contenutoo quello della diagnosi di 'Spasmo emimasticatorio' definito seguendo la metodica elettrofisiologica della H-reflex eteronima. Questo conclusione ritornerà utile quando ripeteremo lo stesso procedimento per altri casi clinici in cui lo è aggiornato all'output del database.
Per approfondire la descrizione metodologica della 'Heteronimous H-Reflex' si rimanda il lettore a seguire la Appendice 1.
Bibliography
- ↑ Jérôme Dockès, Gaël Varoquaux, Jean-Baptiste Poline. Preventing dataset shift from breaking machine-learning biomarkers.GigaScience, Volume 10, Issue 9, September 2021, giab055,
- ↑ Alexander D’Amour et al. Underspecification Presents Challenges for Credibility in Modern Machine Learning. Journal of Machine Learning Research 23 (2022) 1-61,Submitted 11/20; Revised 12/21; Published 08/22
- ↑ Damien Teney, Maxime Peyrard, Ehsan Abbasnejad. Predicting Is Not Understanding: Recognizing and Addressing Underspecification in Machine Learning.ECCV 2022: Computer Vision – ECCV 2022 pp 458–476Cite as
- ↑ Herper M. MD Anderson benches IBM Watson in setback for artificial intelligence in medicine. Forbes. 2017 February 19. [Ref list]
- ↑ 5.0 5.1 G S Handelman, H K Kok, R V Chandra, A H Razavi, M J Lee, H Asadi. eDoctor: machine learning and the future of medicine.J Intern Med.2018 Dec;284(6):603-619.doi: 10.1111/joim.12822. Epub 2018 Sep 3.
- ↑ Schwarzer G, Vach W, Schumacher M. On the misuses of artificial neural networks for prognostic and diagnostic classification in oncology. Stat Med 2000; 19: 541–61.
- ↑ Abdi H. A neural network primer. J Biol Syst 1994; 02: 247–81.